
HBase Simplified: Your Guide to Scalable Big Data Management

HBase is a distributed, scalable, and NoSQL database built on top of the Hadoop Distributed File System (HDFS). It is designed to manage large volumes of sparse data (data with many empty fields. For example, in a dataset with 100 columns, a particular record might only have values in 10 of those columns, while the remaining 90 are empty) in a fault-tolerant manner.
HBase is also a column-oriented database, meaning it stores data by columns rather than by rows.
First Let’s see What Column-Oriented Storage Means:
In a column-oriented database like HBase, data is stored and retrieved by columns rather than by rows. This differs from traditional row-oriented databases, where all the data for a single record (or row) is stored together.
Let's consider a simple example of user preferences on a website.
Suppose we have a table that stores data about whether users like various categories such as Movies, Music and Sports.

In a row-oriented database, all the data for a single user (row) is stored together. This means each record is stored as a complete unit, including any null or empty values.
Here’s how the data is stored:
Row 1: [1, Yes, No, Yes]
Row 2: [2, No, Yes, (null)]
Row 3: [3, (null), Yes, Yes]
To access specific columns like Likes_Movies, you would need to scan through every row, which can be inefficient for large datasets.
In HBase, data is stored by columns rather than by rows, and related columns are grouped into column families.
Suppose we group the columns into two column families:
cf1: General preferences (storing Likes_Movies and Likes_Music)
cf2: Activity preferences (storing Likes_Sports)
How Data is Stored:
Column Family cf1:
Likes_Movies: User 1: Yes, User 2: No
Likes_Music: User 1: No, User 2: Yes, User 3: Yes
Column Family cf2:
Likes_Sports: User 1: Yes, User 3: Yes
Column Families are created by the user or database administrator when defining the table schema in HBase. They are specified at the time of table creation and remain fixed for the lifetime of the table.
This grouping allows HBase to efficiently store and retrieve related columns together, optimizing query performance.
HBase Architecture
HBase’s architecture is designed for horizontal scalability, meaning you can add more servers (RegionServers) to the cluster to handle increasing data and workload rather than upgrading existing servers (vertical scaling). This architecture is crucial for handling big data efficiently.
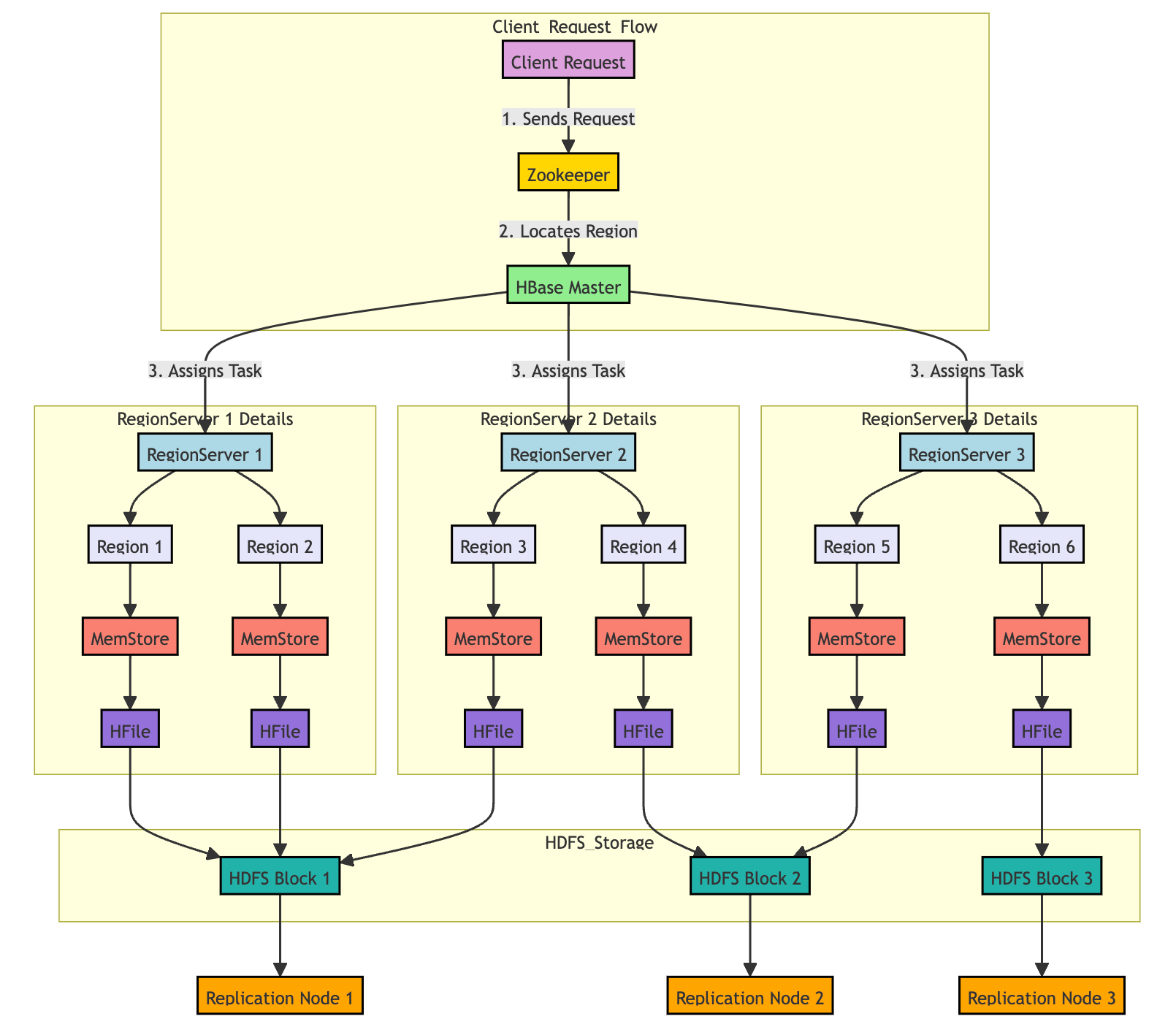
HBase is composed of multiple components that work together to store and manage large datasets. These components include the following:
HBase Master:
The HBase Master is responsible for managing the cluster. This includes assigning regions to RegionServers, managing schema changes, and balancing the load across RegionServers.
It does not handle data requests directly; that’s the job of the RegionServers.
RegionServer:
Each RegionServer manages a subset of the table’s data called regions. It handles all read, write, and update requests for the regions it manages.
If a region becomes too large, it is split into smaller regions, which can then be distributed across different RegionServers to balance the load.
Regions:
Regions are the basic units of scalability in HBase. Each region holds a subset of the table’s data, and these regions are spread across multiple RegionServers.
A table is split into multiple regions based on the row key range, allowing HBase to scale horizontally by distributing these regions across different servers.
MemStore:
When data is written to HBase, it is first stored in the MemStore, an in-memory structure within the RegionServer. This allows for fast write operations.
The data in the MemStore is periodically flushed to disk into HFiles once it reaches a certain threshold.
HFiles:
HFiles are the actual storage files where data is persistently stored in HDFS. Each column family in HBase is stored in a separate set of HFiles.
When data is read, it is retrieved from both the MemStore (for the most recent data) and the HFiles (for older data stored on disk).
HDFS:
HBase stores its data in HDFS (Hadoop Distributed File System), which ensures data is replicated across multiple nodes for fault tolerance.
Zookeeper:
Zookeeper acts as a coordinator for HBase, managing distributed synchronization and ensuring that there is only one active HBase Master at a time.
It also keeps track of the status of RegionServers and helps clients locate the regions.
Now that we understand the architecture, let’s explore how data is written to and read from HBase.
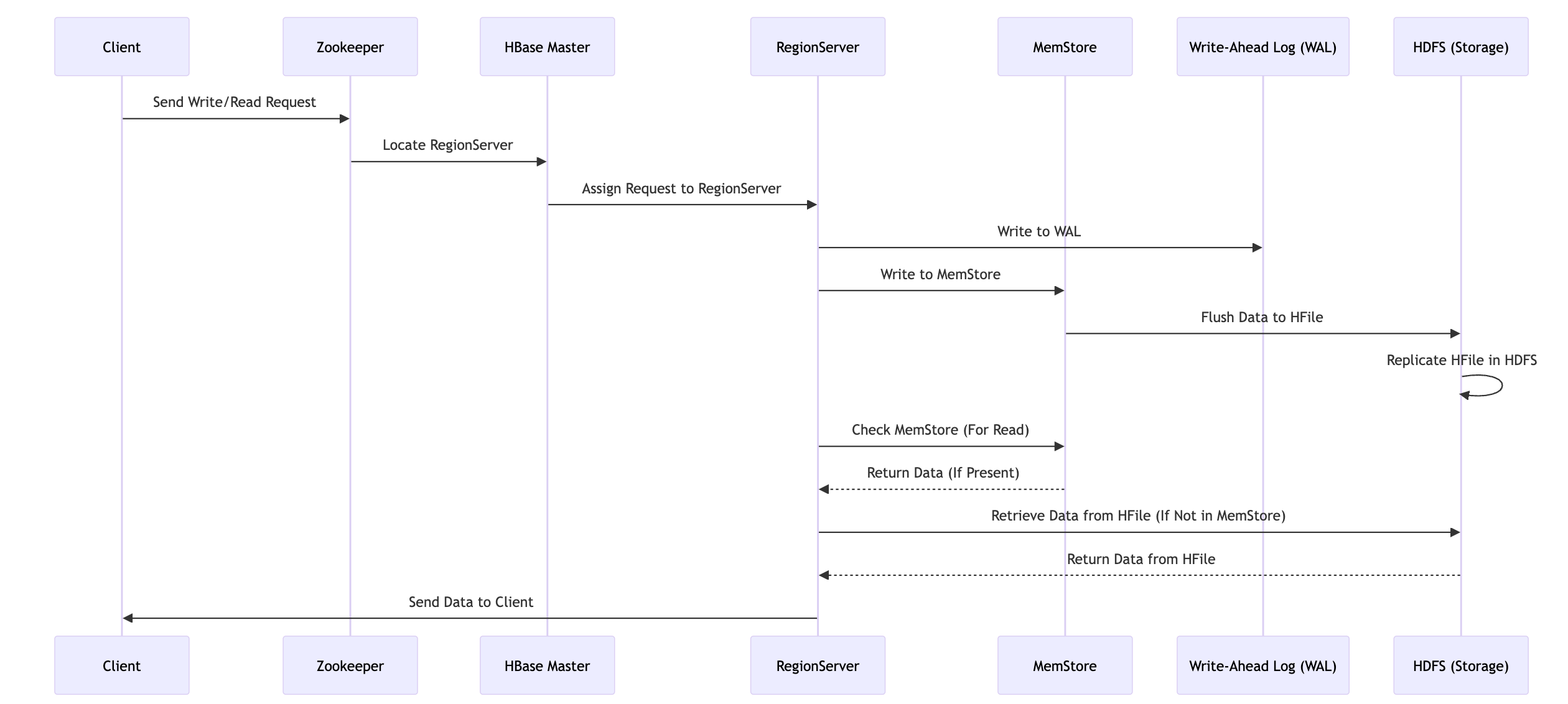
What Happens When a Write Request is Made?
When a client sends a write request to HBase, the system processes the data in several stages to ensure both efficiency and durability:
Client Request: The client initiates a write request to store data in HBase.
Zookeeper Coordination: Zookeeper identifies which RegionServer is responsible for handling the specific row key associated with the data.
RegionServer Assignment: The HBase Master, informed by Zookeeper, assigns the write operation to the correct RegionServer.
Write to MemStore and WAL:
MemStore: The data is first written to the MemStore, an in-memory store within the RegionServer. Writing to MemStore is fast because it’s in-memory.
Write-Ahead Log (WAL): Simultaneously, the data is also written to the WAL. This ensures durability because if the RegionServer fails, the data can be recovered from the WAL.
Flushing to HFile:
As data is written to HBase, it first accumulates in the MemStore, an in-memory component within the RegionServer. However, this data doesn't stay in the MemStore indefinitely. Instead, it is eventually flushed to disk, becoming part of a permanent storage structure known as an HFile.
When Does Flushing Occur?
Size Threshold: As the MemStore accumulates data, it eventually reaches a threshold size (by default, 64 MB per region per column family). Once this threshold is reached, the data in the MemStore is automatically flushed to an HFile.
Flushing Process: During the flush, all the data stored in the MemStore is written to an HFile, ensuring that the in-memory data is persisted to disk
Storage in HDFS: The newly created HFile is then stored in HDFS, Hadoop's distributed file system. HDFS ensures that the HFile is safely and durably stored across multiple nodes, providing fault tolerance and high availability.
Replication in HDFS: The HFile stored in HDFS is replicated across different nodes to ensure fault tolerance and data availability.
What Happens When a Read Request is Made?
When a client requests data from HBase, the system follows these steps to retrieve the data:
Client Request: The client sends a read request to HBase.
Zookeeper Coordination: Zookeeper helps identify which RegionServer holds the region containing the requested data.
RegionServer Assignment: The HBase Master assigns the request to the correct RegionServer based on the row key.
Data Retrieval:
Check MemStore: The RegionServer first checks the MemStore to see if the data is available there. Since MemStore holds the most recent data, this is the quickest way to retrieve the information.
Check HFiles: If the data isn’t in MemStore, the RegionServer will look in the HFiles stored in HDFS. This involves reading from disk, which is slower than reading from MemStore but necessary for retrieving older or less frequently accessed data.
Return Data: Once the data is found, it is sent back to the client.
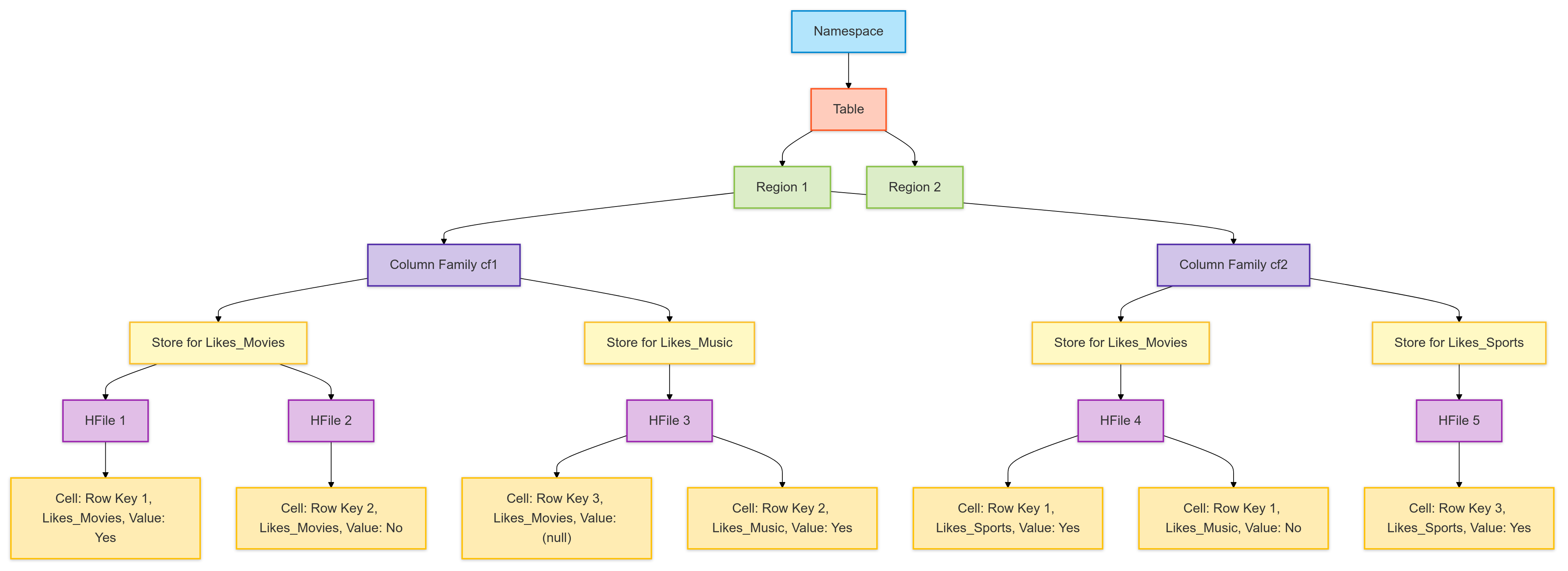
HBase Data Storage Hierarchy
HBase organizes data in a hierarchical structure, from the top-level namespace to the individual data cells stored in HFiles on HDFS. Understanding this hierarchy is crucial for effectively managing and optimizing HBase.
HBase Namespace - A logical grouping of tables that helps organize and manage them collectively.
Examples:
default(default namespace)test(testing environmentprod(production environment)
Table - A collection of rows, where each row is identified by a unique row key. Tables are divided into regions to enable distributed storage and processing.
Examples:
my_tablewithin thedefaultnamespace.
Region - A subset of a table's data that contains a range of row keys. Regions are the basic unit of scalability in HBase and are managed by RegionServers. As data grows, regions are split and distributed across multiple RegionServers.
Examples:
A region storing rows with keys .
Column Family - A group of related columns that are stored together on disk in HFiles. Column families are defined at table creation and cannot be changed afterward. Each column family is stored separately, allowing for efficient data retrieval.
Example:
cf1(General preferences)cf2(Activity preferences)
Store - The storage structure within a region for a specific column family. Each store manages multiple HFiles for the data in that column family within a region.
Example:
A store for column family
cf1in a specific region.
HFile - An immutable file format used by HBase to store data on HDFS. HFiles are created during flushes (when data is moved from memory to disk) and compactions (when multiple HFiles are merged).
Example:
An HFile containing data blocks, meta blocks, and a file trailer.
Cell - The smallest unit of data storage in HBase, representing the intersection of a row key, column family, and column qualifier. Each cell stores a value along with a timestamp to manage versions of the data.
Example:
Row key
1, column familycf1, column qualifierLikes_Movieswith valueYes.
Final Thoughts:
HBase is ideal for managing large-scale, distributed data where real-time read/write access is essential. Consider using HBase when:
Handling Massive Datasets: HBase scales horizontally, making it suitable for petabytes of data across multiple servers.
Real-Time Data Access: If your application needs low-latency access for both reads and writes, HBase is optimized for this.
Managing Sparse Data: HBase’s column-oriented storage efficiently handles datasets with many empty fields.
Dynamic Schemas: HBase allows adding new columns on the fly, making it flexible for evolving data structures.
Use HBase when you need scalable, real-time access to large, complex datasets, particularly when traditional databases may not suffice.